Character
Introduction
Character is another central category in literary studies that humans are well-trained to make sense of and produce multiple interpretations of, including psychological features, appearances, and the reader's sentiment towards them.
Again, these are not easy for a computer to extract, but the grounds for which readers make conclusions about characters may also not be completely consistent with the complex set of information that a text produces.
One immediate useful way of approaching characters with computers is by looking at the context of words related to various characters of texts. This can be done heuristically with the aim of covering all the places a certain character has been mentioned as well as more systematically, for example, by comparing the words associated with groups of characters.
Applications
Elementary
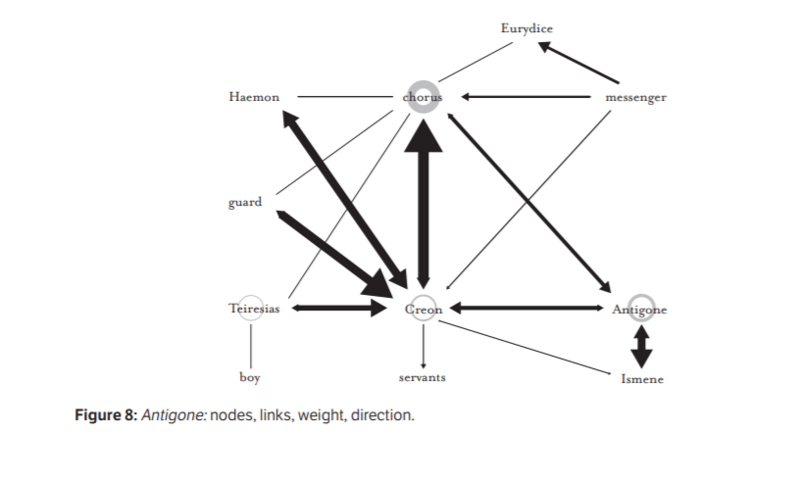
Calculate the word-space of different characters within a single text. Word-space is a measurement of how many of a text’s words are allocated to certain characters. This is done quite simply when analysing works within the dramatic genre, since the entire cast of characters often have their own easily discernible lines. It is therefore possible to count how many words are used in a single play, and then measure what percentage of a play’s total words that is spoken by each character. To name just one example of an interesting result this approach might generate, it would perhaps surprise many contemporary readers that both the chorus and Creon speak more in Sophocles’ Antigone than the play’s namesake heroine. See Franco Moretti’s influential pamphlet “Operationalizing” for an expanded introduction to the concept as well as its role in more advanced digital approaches to the study of character.
Another way to look at the context of words related to different characters is using the Key Word In Context (KWIC) concordance function offered by Voyant Tools. This function allows you to investigate co-occurrences of words or characters and explore which words occur often in the proximity of character names.
Advanced
Compared to plays, novels can be more ambiguous when turning text into word-space - it is not clear how to allocate words in a sentence to a particular character. An alternative way to computationally measure and analyse character-space is by use of a network model. A character network consists of nodes and edges between the nodes; characters being the nodes and their interactions the connecting edges . The ‘weight’ of an edge can be adjusted in two ways. First, the number of exchanges between two characters makes the weight grow, and the edge becomes more significant in the whole network. Second, arrows can add information about the direction of interaction, who is addressing who in the interactions. This way, the concept of character can become operationalized through quantification, as Moretti discusses (2014). The visual nature of the analysis allows for further interpretation of character dynamics, possibly revealing aspects that remain undiscovered in a traditional literary analysis.
Compare the work on novels with Fischer’s project of network analysis on plays. Generate a character network on a book of your choice (for instance Project Gutenberg offers over 60 000 literary works to choose from). For a more technical approach, David Bamman’s BookNLP offers a pipeline to preprocess and model literary characters in a Bayesian framework.
Resources
Scripts and sites
- For inspiration and descriptions of how to do network analysis of dramatic texts, see this page, and Fischer's posters.
- Code used for The Dramavis project by Frank Fischer to generate character networks of dramatic texts.
- David Bamman’s BookNLP pipeline.
- Geoffray Rockwell Python script for named entity recognition (Tapor Coding Tools)
- An introduction to Voyant Tools’ Keywords in Context tool and guide to how it can be used (using the works of Jane Austen as an example).
Articles
-
Bamman, D., Underwood, T., & Smith, N. A. (2014, June). A bayesian mixed effects model of literary character. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. (Volume 1: Long Papers) (pp. 370-379). https://www.aclweb.org/anthology/P14-1035
-
Fischer, F., Göbel, M., Kampkaspar, D., & Trilcke, P. (2015). Digital Network Analysis of Dramatic Texts. Proceedings of DH2015. http://dh2015.org/abstracts/xml/FISCHER_Frank_Digital_Network_Analysis_of_Dramati/FISCHER_ Frank_Digital_Network_Analysis_of_Dramatic_Text.html
- Moretti, F. (2013). 'Operationalizing': or, the function of measurement in modern literary theory. Stanford Literary Lab. Pamphlet 6. https://litlab.stanford.edu/LiteraryLabPamphlet6.pdf