Tropes
Introduction
The ability to identify tropes is essential to literary studies, and one of the sources for the complexity of literature. In particular, poetry may, with a few words, create highly complex, compelling imagery.
Consider Ezra Pound's famous poem, In a Station of the Metro: "The apparitions of these faces in the crowd/Petals on a wet, black bough." Read literally, the poem presents two very different things, faces, and petals, but few readers would argue that one is not justified in reading petals as a metaphor for the faces.
So far, so good, but how do the attributes of the petals relate to the faces? There is plenty to argue about, and in many ways; this is a sign of literature’s vibrant capacity to engage readers and make them disagree over interpretations. Computationally, tropes are more complex, and even identifying the petals would be challenging, as there is no helping "are like" to connect the two images.
Research in Natural Language Processing has addressed trope detection for many years, but with varied results. Building a catalogue of metaphors does not capture what literature is particularly good at, namely, surprising and creative language use.
Finding "dead metaphors" and clichés could be useful in some instances, but also seems unambitious. Browsing texts for words related to "like" may also yield results, but would fail to capture what is interesting about Pound's poem.
As in other fields, machine learning has been employed to train a neural network to determine whether or not an expression includes a metaphor. These are far from perfect, but may perform well enough to indicate whether the use of metaphors in corpora changes over time.
Another side of computational methods and tropes is the potential for computers to be creative and create tropes, not based on putting together randomly-selected words from lists, which would often produce haphazard random results, but by putting a neural network "in reverse," and creating metaphors, rather than recognizing them (more on text generation under creative writing).
Applications
Elementary
To date, the most reliable, but most time-consuming, approach is manual annotation: This means using clear and systematic guidelines to annotate metaphors with the help of digital annotation tools (such as CATMA, brat, or the UAM corpus tool).
Any computer-based metaphor study, whether it uses annotation or automatic detection, is necessarily “formalistic.” This means making the procedure more external and making a number of explicit decisions. For example, one needs to explicitly specify the types of metaphors one wishes to study by using an operational definition based on concrete examples.
Another option for identifying metaphorical language is using additional semantic resources, such as semantic taggers (e.g. WMatrix) and thesauri (e.g. WordNet).
Advanced
Automated solutions exploit resources such as WordNet and lexical ontologies, knowledge extraction from free (web) text, and statistical methods based on distributional association measures, vector space models, supervised learning, clustering, and topic modeling.
So far, natural language processing (NLP) has been applied only seldom to specifically literary metaphor detection. In this line of metaphor research, a fundamental methodological question is whether to use hand-engineered features or unsupervised and deep learning. When considering features, the research diverges on the kind of information that should be included in the computational models, such as lexical and syntactic information, higher-level features such as semantic roles or domain types, concreteness, imageability, or WordNet super senses. Another question concerns whether a metaphor is detected at word level or higher, and whether the aim is to detect linguistic forms or also the conceptual structure.
Most recently, shared metaphor-detection tasks show an upward trend in precision and recall (measures of the number of correctly identified relevant instances), specifically since the advent of deep learning and vector-space models in computational semantics. A new type of metaphor study combines computational resources with extra-linguistic reader-response measures (familiarity, ease of interpretation, semantic relatedness, and comprehensibility). Other approaches make progress in metaphor paraphrasing, which is a form of interpretation.
Resources
Scripts and sites
-
Mapping metaphor, with the historical Thesaurus project (English language).
-
VUAMC corpus, subsection of British National Corpus annotated for metaphor, including fiction sample.
-
EAK corpus (German narrative beginning sections annotated for metaphor).
- the UAM CorpusTool, an open-source text corpora annotation tool.
-
Annotation Studio, a collection of web-based and collaborative annotation tools.
-
CATMA, a computer-assisted text annotation and analysis tool.
-
Brat, an online environment for collaborative text annotation.
- Wmatrix for corpus analysis and comparison, offering annotation tools and standard corpus linguistic methodologies.
Articles
- Dallachy, F. (2016). The Dehumanized Thief. In Anderson, W., Branwell, E., & Hough, C. (Eds.) Mapping English Metaphor Through Time. (pp. 208-220). Oxford University Press. https://oxford.universitypressscholarship.com/view/10.1093/acprof:oso/9780198744573.001.0001/acprof-9780198744573-chapter-13
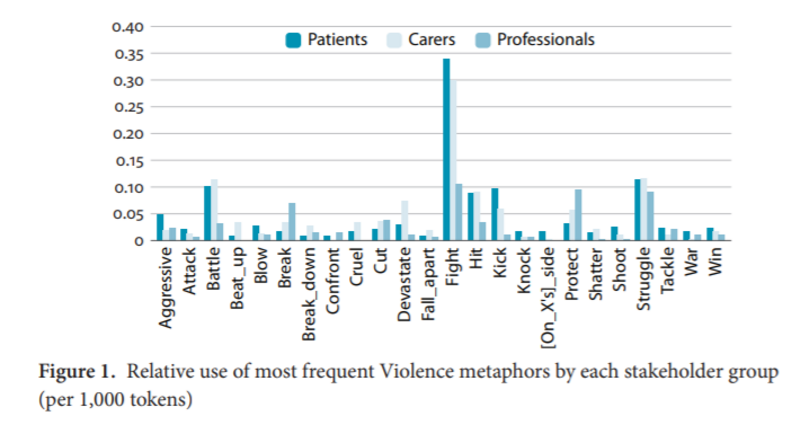
- Demmen, Jane, et al. (2015). A computer-assisted study of the use of Violence metaphors for cancer and end of life by patients, family carers and health professionals. International Journal of Corpus Linguistics, 20(2). (pp. 205–231). https://doi.org/10.1075/ijcl.20.2.03dem
- Peng, C., Vu, D. T., & Jung, J. J. (2021). Knowledge graph-based metaphor representation for literature understanding. Digital Scholarship in the Humanities. https://doi.org/10.1093/llc/fqaa072
- Tanasescu, C., Kesarwani, V., & Inkpen, D. (2018, May). Metaphor detection by deep learning and the place of poetic metaphor in digital humanities. In The Thirty-First International Flairs Conference. https://dial.uclouvain.be/pr/boreal/object/boreal:249759