Archive
Introduction
An archive essentially constitutes a collection of documents, which, with some work, can become a corpus or a data set, to be used for further research.
As a thought experiment, we suggest you reflect on word cognates from other fields that denote roughly a similar idea of a collection. Also consider the differences between an archive and a data set derived from it.
Where we normally look for individual insights or discoveries in an archive, computational tools allow us to manipulate it as a single unit, to extract trends, and to build models that encompass multiple documents. In doing so, a researcher must not treat archives as neutral or natural reflections of the times past. For example, the papers of Toni Morrison at Princeton provide a window onto the author's intellectual life as narrated through her letters and manuscripts, but not book reviews or scholarly articles. The understanding of an archive's history—institutional, political, cultural—will ensure that any claims deriving from the underlying documents can better correspond to the resulting insight. Computational work within archives, in other words, must proceed from a contextual understanding of their history.
Applications
Elementary
A great variety of computational tools are available for the work with text or image archives (working across media, however, can pose a significant challenge). It is always wise to begin with exploratory, descriptive tools. If you are interested in the concept of "justice" in the 19th century, for example, you can begin by asking what words were used to describe justice? How often do they appear? How does the lexicon surrounding these concepts change over time or in response to specific events?
Advanced
When working with archives computationally, beyond historical description, researchers are often interested in the content of archival documents and further in the patterns that such content may reveal over time. To generalize from documents to patterns, the archive must be transformed in what may be termed the "document analysis pipeline." Such a pipeline moves an analogue document from its original format (on paper, for example) into its digital representation, and then, in a series of transformative states, on to content extraction, data cleaning, analysis, modeling, and visualisation.
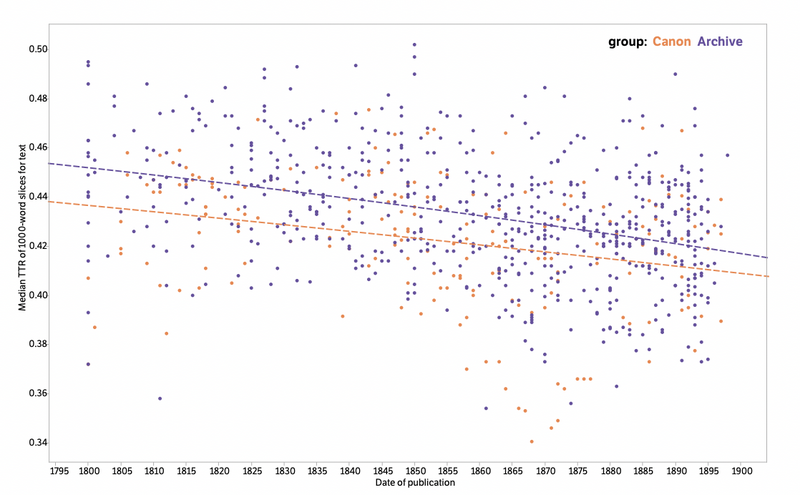
Regardless of the source of your records, it is important to consider how you acquire records, why you acquire them, and what records are collected. Therefore, an analysis of archives should always start with pen and paper to understand the historical context and relevance in relation to the research question. As the pamphlet “Canon/Archive. Large-scale Dynamics in the Literary Field” shows, it is not easy to tackle the topic of archives. Digitalisation might bias us to use easily available resources, known authors - the canon.
To put it the other way round, what can a dataset tell about an archive? Read Ted Underwood’s blog post to explore how a sample of corpus extrapolates beyond the given data. A similar idea is to make sub-corpus topic models to map the “great unread” (Tangherlini & Leonard, 2013). Replicate Underwood’s analysis from his GitHub Repository, or apply the same methods on your own corpus retrieved from another archive to see what a smaller corpus can tell about the bigger digital archive.
Resources
Scripts and sites
- Internet Archive, a non-profit digital library, having a collection of over 20,000,000 books and texts freely available.
- Pace of change, a GitHub repository by Ted Underwood to explore an archive.
Articles
-
Algee-Hewitt, M., et al. (2016) Canon/Archive. Large-scale Dynamics in the Literary Field. Stanford Literary Lab Pamphlet 11. https://litlab.stanford.edu/LiteraryLabPamphlet11.pdf
- Aljoe, N. N., Dillon, E. M., Doyle, B. J., & Hopwood, E. (2015). Obeah and the early caribbean digital archive. Atlantic Studies, 12(2), 258-266. https://doi.org/10.1080/14788810.2015.1025217
-
Klein, L. F., Eisenstein, J., & Sun, I. (2015). Exploratory thematic analysis for digitized archival collections. Digital Scholarship in the Humanities, 30(suppl_1), i130-i141. https://doi.org/10.1093/llc/fqv052
-
Smith, D. A., Cordell, R., & Mullen, A. (2015). Computational methods for uncovering reprinted texts in antebellum newspapers. American Literary History, 27(3), E1-E15. https://doi.org/10.1093/alh/ajv029
-
Tangherlini, T. R., & Leonard, P. (2013). Trawling in the Sea of the Great Unread: Sub-corpus topic modeling and Humanities research. Poetics, 41(6), 725-749. https://doi.org/10.1016/j.poetic.2013.08.002
-
Underwood, T., & Sellers, J. (2015). How Quickly Do Literary Standards Change?. Figshare. May, 19. https://figshare.com/articles/journal_contribution/How_Quickly_Do_Literary_Standards_Change_/1418394