Ethnicity
Introduction
While race and ethnicity have become central categories of literary analysis over the last several decades, they have proven difficult to address via quantitative methods. This discrepancy between disciplinary primacy and methodological marginality has several causes. For one, ethnicity is difficult: difficult to define, difficult to identify in complex texts, difficult to isolate over historical time, and difficult to operationalize as a quantifiable feature of literature. Linking race and ethnicity to quantification also has unhappy resonances with eugenics (and worse) and with the disputed status of cliometrics (quantitative economic history) in the 1960s and 1970s.
When working with the topic of ethnicity, it becomes evident that computational models are constructions - they aim at representing the social reality but are always mere simplifications. Sinykin, So, and Young (2019) remind that quantitative modeling involves human reasoning and interpretation at each step. When assessing the use of economic language by race, discussed further in the next section, the researchers had to identify both the relevant set of terms for economics and the race of the authors. This was annotated manually in their data set. Thus, behind the numeric results of the statistical models, human decisions and careful thinking are always present. As to bigger corpora or predictive models, the ethnicity or gender of an author is based on approximations and requires categorical decisions that do not fully reflect the complexity of the “real” world.
Finally, much critical work on ethnicity helps us to understand how ethnic categories are contingent, multiple, overdetermined, and socially contingent, meaning that attempts to treat textual ethnicity as a binary classification problem risk missing the point of exactly the critical framework they seek to elucidate. For these reasons, much of the best existing quantitative work on race and ethnicity has focused on measuring participation and market access on the part of self-identified minority writers and on archival digitization projects that seek to expand the range of texts available to computational scholarship in the future. But machine learning is beginning to make inroads in the field as scholars have sought to exploit its ability to assess document (and author) membership across several categories and to reflect the judgements of diversely situated readers.
Applications
Elementary
A way to approach ethnicity quantitatively would be to compile bibliographies of authors with different racial identities and compare their representation and success through different measures. For instance, you can compute basic statistics using data regarding publications, book reviews, bestseller lists, book sales, and prices available on sites such as Goodreads and consider how these numbers change over time or depend on ethnicity.
In his book Redlining Culture, Richard Jean So (2020) draws on such data to highlight a historical persistence of an extreme bias toward white authors in the U.S. literary field in the years between 1950 and 2000. For instance, 98% of novelists appearing on the US bestseller lists between 1950 and 2000 are white, white authors represent 90% of the most reviewed novelists in magazines such as the New Yorker, and white authors comprise 91% of novelists who’d won major awards such as the Pulitzer. This is all despite the fact that white people represent just 75.1% of the overall U.S. population in 2000.
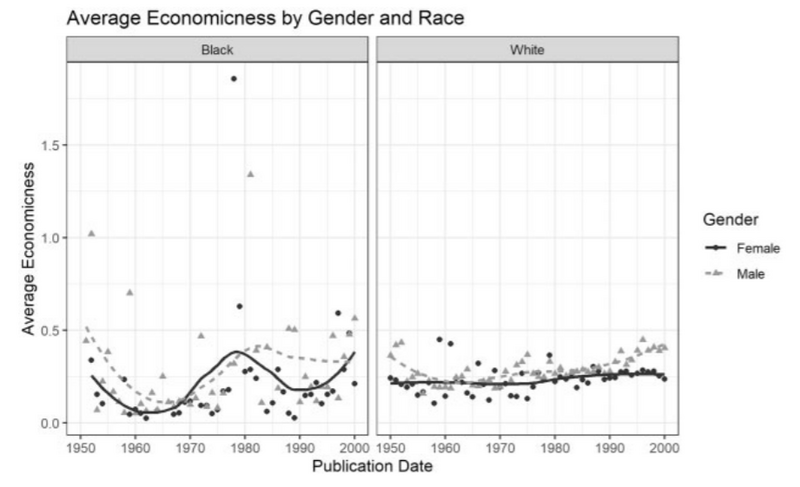
To give a concrete example, racial inequality in the literary field is explored in Sinykin et. al’s paper, “Economics, Race, and the Postwar US Novel: A Quantitative Literary History” (2019). Their model, built upon ODE (the Oxford Dictionary of Economics), aimed at assessing the “economicness” of a corpus of 5931 U.S. digitized novels. By investigating the differences in language used by minority and majority authors in the chosen corpus, they analysed the extent to which normative economic language has penetrated novelistic discourse over time. More specifically, they counted the normalized ratio of economic terms from the ODE in each work of the corpus. These scores could be plotted across a selected time period. Their investigation revealed that female authors of novels within the chosen corpus used 20% less economic terms than male authors, while African Americans used 10-15% fewer than white authors, reflecting the historical privilege associated with white men. Moreover, they found that the economic language of black women’s writing changed from a downturn in the late 1970s to an equally rapid reversal starting in the mid-1990s, suggesting that within 15 years, black women writers started to extend their representation of the economy.
It is, however, important to contemplate the limitations and weaknesses of such computational approaches. In the example above, the generated model was incapable of detecting e.g. tropes of terms such as slavery that could also be regarded as an economic discourse and would have been identified by close reading. This illustrates how quantitative findings from distant reading can very often benefit from being combined with findings from close reading.
For another approach on word usage trends, use Google Ngram Viewer to explore the use of terms that might have ethnic connotations. Have a look at the words used by Algee-Hewitt, M., Porter, J. D., & Walser, H. (2020) to get a sense of what kind of words and co-occurrences might be interesting to track.
Advanced
Despite the challenges discussed above, statistical models allow for making interesting inferences that reflect phenomena in social reality. In the case of ethnicity, statistical models can shed light on what ethnic groups get represented on the literary scene - whose voice gets heard. With the help of named entity recognition (NER) algorithms to detect named locations and geocoding services to associate those locations with specific geographic coordinates, it is possible to map which parts of the world get represented in literature, working as a proxy for ethnicity. A good example of this is Evans and Wilkens’s article (2018), visualising what kind of world is presented in British fiction. Compare their world maps drawn with four different data sets. Based on the results, reflect on the importance of corpus selection when exploring ethnicity and arguing for a fair representation.
Another proxy for ethnicity is the nationality of the author. From Goodreads, the author profiles often include their hometown. Scrape author and user information from Goodreads, and explore where popular authors come from. If you are familiar with statistical analysis, you can also investigate if there is correlation between user location and their preferred authors. Can you cluster books that are often read together? Use geocoding applications (see tutorials offered by Programming Historian) to visualise the ethnic distribution of authors or books.
To build further upon the aforementioned observations, have a look at Wilken’s unsupervised machine learning models for genre clustering (2016). In his work, author genders and ethnicities were included in the model. Build similar models, with and without this extra-textual information and observe how it affects the classification results. Wilkens’ dataset can be found on Harvard’s dataverse.
Resources
Scripts and sites
-
Tutorials for geomapping in Programming Historian.
-
Tutorial for exploring authors on Goodreads, including gender and geographic information.
-
A HathiTrust Dataset of English language literature with geographic locations.
- Google Books NGram Viewer, an online search engine that plots the frequencies of any set of search strings as n-grams.
- Interactive maps for British literary geography, 1880-1940, by Matthew Wilkens.
Articles
-
Algee-Hewitt, M., Porter, J. D., & Walser, H. (2020). Representing Race and Ethnicity in American Fiction, 1789-1920. Journal of Cultural Analytics, 12, 28-60. https://doi.org/10.22148/001c.18509
-
Evans, E., & Wilkens, M. (2018). Nation, Ethnicity, and the Geography of British Fiction, 1880-1940.https://doi.org/10.22148/16.024
-
Sinykin, D., So, R. J., & Young, J. (2019). Economics, race, and the postwar US novel: a quantitative literary history. American Literary History, 31(4), 775-804.https://doi.org/10.1093/alh/ajz042
-
So, R. J. (2020). Redlining Culture: A Data History of Racial Inequality and Postwar Fiction. Columbia University Press. https://cup.columbia.edu/book/redlining-culture/9780231197731
- So, R. J. (Ed.). (2021, April). Issue 7: Post45 x Journal of Cultural Analytics. https://post45.org/sections/issue/p45-ca/
-
Wilkens, M. (2018). Genre, Computation, and the Varieties of Twentieth-Century US Fiction. https://doi.org/10.22148/16.009