Interpretation
Introduction
Hermeneutical and computational approaches are very different and emphasize what humans and machines, respectively, are good at.
Humans can make well-developed statements about a complex text based on numerous observations and inferences that may not be completely clear to themselves, but nevertheless make sense to them and others. In contrast, it is difficult to make computers take the final leap from compiling lots of data about a text and making an actual interpretation (although this may be changing soon as language models such as ChatGPT prove capable of making summarizations and interpretations). However, computational approaches may be used for assisted text analysis.
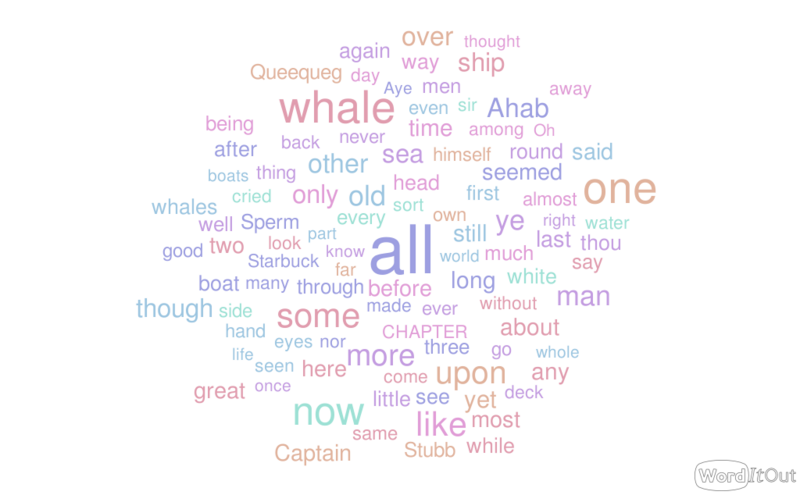
Few readers of James Joyce's Ulysses would know for certain that "like" is one of the most used words in the novel. And fewer, if any, would have noticed that despite being frequently used, it does not appear in long stretches of the text. For a reader of the novel who can tell the difference between the Q&A of the Ithaca chapter and Molly's soliloquy in the final Penelope chapter, this makes immediate sense once you know it.
This kind of assisted analysis bridges the gap between the facts revealed by a computational approach and the meaning attributed to it by a reader. When moving to larger corpora, the divide between the hermeneutical and the computational continues to be important, but with the important difference that the manual reading of thousands of texts is no longer possible, and the role of the computational approach is also to give a sense of a whole that may only be read in parts.
Applications
Elementary
Assisted text analysis, such as using word clouds and lists of word frequencies, can be used to get a different perspective on texts. A word cloud is a way of visually representing which words occur most frequently within a given text, meaning that the more often a word is used, the bigger a font it will get within the word cloud. To follow on from the aforementioned example, if one copies the text of James Joyce’s Ulysses into a word cloud generator, a cluster of words will appear where frequently used words such as “like” will appear in bigger letters than words with fewer occurrences. Many word cloud generators such as Voyant Tools are accessible freely online and allow the user to simply copy-paste a text from an archive or a corpus into the generator, which will then create the word cloud.
Advanced
To further explore the visualisation of world clouds, it is possible to build topic models based on the statistical word frequencies in different topics. Topic modeling is an unsupervised machine learning tool for inferring topics from a set of documents. It detects textual patterns, such as often occurring words or phrases, and clusters similar expressions in groups that best characterise the given set.
One method for topic modeling is Latent Dirichlet Allocation (LDA) which treats every document as a mixture of some topics and every word occurring within the document as attributable to one of these topics. In this way, it is possible to get an overall idea of the content of the documents - although the thematic clusters are still up for human interpretation. Chapter 6 in Text Mining with R offers a good introduction for topic modeling in R. Explore a collection of text documents of your choice by building a topic model. What do the keywords of the clusters reveal?
Resources
Scripts and sites
-
Voyant is a very accessible, yet sophisticated tool for understanding in particular the vocabulary of a text or a small collection of texts. It will be used as a reference for a beginner's tool several times at this site. Voyant is well documented, both at the website and in the book Hermeneutica, written by its creators, Stéfan Sinclair and Geoffrey Rockwell.
-
Another useful resource is TAPoR 3 which has a collection of more than 1500 digital tools that can be used to aid the analysis and interpretation of texts. It has an excellent search engine, which enables filtering after useful criteria, e.g. ease of use or whether it runs on your computer or browser.
- The handbook Text Mining with R introduces the framework of the tidytext package developed for text analysis purposes.
- DARIAH Topics is a python library for topic modeling and visualisation, with hands-on jupyter notebook tutorials.
Literature
- Moretti, F. (2013). 'Operationalizing': or, the function of measurement in modern literary theory. Stanford Literary Lab Pamphlet 6. https://litlab.stanford.edu/LiteraryLabPamphlet6.pdf
- Underwood, T. (2015, June 4). Seven ways humanists are using computers to understand text. https://tedunderwood.com/2015/06/04/seven-ways-humanists-are-using-computers-to-understand-text