Literature
Introduction
A classic question in literary theory is whether it is possible to define literature. Is there a use of language that is distinctively literary, or is literature defined by historical conventions?
The major genres have traits that we recognize readily: plays have stage directions and names of characters to indicate who speaks, poetry usually has lines of uneven lengths, whereas prose does not. This is relatively simple to formalize but it only captures conventions. How do we separate prose fiction from non-fiction prose? Can language itself reveal it?
A computational approach includes both a practical and a philosophical side to work on this problem. When selecting texts from a large corpus, it is useful to be able to distinguish fiction from non-fiction. Sometimes metadata, that is data that is not part of the digitized text as such but data that provides information on the text, will ease this task, but often, vast archives of digitized texts do not have adequate metadata, hence it may be necessary to find other ways to define what counts as belles lettres.
The philosophical aspect is concerned with how far it is possible to formalize what we mean by literature. As it is often the case in computational studies, the task of explaining a problem in a way that may be formalized initiates a discussion of whether distinguishing features exist.
Applications
Elementary
Calculate the type/token ratio for different literary and non-literary texts and compare them. A type/token-ratio is a way to measure the lexical variation in a text or a segment of text. It is done by first counting the total number of words used, this number is referred to as the token. The type is then the amount of unique words occurring in the text, where a grammatical variation will be seen as a new unique word – this means that words occurring several times will only be counted once. The type-token ratio is then calculated by taking the amount of total words (token) and dividing it with the number of unique words (type). For a more sophisticated and innovative way of distinguishing levels of literariness or genres, see both Stanford Literary Lab Pamphlet 11 and Lijffijt and Nevalainen’s “A simple model for recognizing core genres in the BNC” below.
Advanced
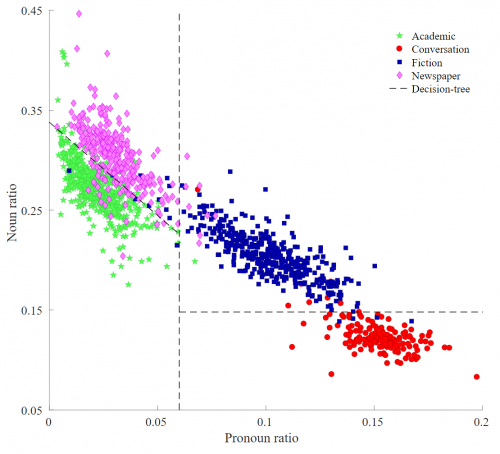
Machine learning algorithms can be trained to classify data by relevant features, and this approach can also be adapted for distinguishing non-fiction from fiction. Previous research has suggested three classes of features that can be used in text classification: fiction might differ from non-fiction at the low level (character and token counts), high level (lexical and syntactic characteristics) and in their derived features, such as type-token ratio mentioned above, average word length, or sentence length. It might even be possible to discover new patterns to which the human eye is blind when reading.
Use your literary intuitions to build a classification model for fiction/non-fiction texts. How well does it perform with different linguistic features? Since this classification task is of binary nature, you can try implementing a logistic regression, as Ranjan et. al. (2019) have done. For instance, they found out that adverb/adjective ratio and adjective/pronoun ratio were good category predictions. The brown corpus from Python nltk package can be useful to create a training corpus, as all files are tagged with a genre under the head categories of Informative prose and Imaginative prose that can be used as the fiction/non-fiction classes. Moreover, the scikit-learn package offers great tools for machine learning.
It is also possible to study literary features in a text, an approach called stylometry, through computational applications. Use stylometric analysis to explore and classify writing style in a set of documents. For instance, see Elahi and Muneer’s work on classifying literary style, and see how the results differ on fiction and non-fiction texts.
Resources
Scripts and sites
-
The scikit-learn package offers very helpful tools for machine learning in Python.
-
NLTK is a platform for natural language processing in Python, providing over 50 corpora and useful functions for analysing human language.
- Project Gutenberg, a free eBook library.
- GitHub repository with code for Stylometric analysis of writing style
Literature
- Algee-Hewitt, M., et al. (2016) Canon/Archive. Large-scale Dynamics in the Literary Field. Stanford Literary Lab Pamphlet 11. https://litlab.stanford.edu/LiteraryLabPamphlet11.pdf
- Lijffijt, J., & Nevalainen, T. (2017). A simple model for recognizing core genres in the BNC. In Big and rich data in English corpus linguistics: methods and explorations (Vol. 19). University of Helsinki, VARIENG eSeries. http://hdl.handle.net/1854/LU-8574176
- Piper, A. (2016) Fictionality. Journal of Cultural Analytics. https://doi.org/10.22148/16.011
- Qureshi, M. R., Ranjan, S., Rajkumar, R., & Shah, K. (2019, August). A Simple Approach to Classify Fictional and Non-Fictional Genres. In Proceedings of the Second Workshop on Storytelling (pp. 81-89). http://dx.doi.org/10.18653/v1/W19-3409