Quality
Introduction
Who decides what good literature is? Even if we trust the processes of canonization to maintain the best works in the collective memory to some degree, we also know that there are many standards, many biases, and many individual idiosyncrasies that make the question of quality complicated.
Computational methods have made it easier to study literary canonization, popularity, and markets. With online fora such as Goodreads, there are even sources for understanding what cohorts of readers think of certain works. Another resource recently available is Open Syllabus, a project that has digitized millions of college syllabi - including in the field of literature – that gives a sense of which authors and titles are popular in teaching literature, making up the institutional canon. Such metrics are not flawless, but they are also hard to ignore as indications of what is perceived as valuable in literary and reading cultures. Moreover, data on translations, sales, valuations, re-editions, and so on, may be useful for criticizing fixed ideas about what are regarded as canonical works.
With a new wealth of resources, the question becomes even more pertinent whether literary quality can be thought of as one unified standard, or whether we should instead assume there to be literary qualities that are different across groups of readers, such as between scholars or prize-committees and laymen readers. Resources like Open Syllabus and GoodReads are not necessarily aligned in estimating literary quality or success but represent different communities of readers and organizational structures that each reflect different literary tastes and preferences for certain works, authors or genres. Still, studies such Walsh and Antoniak’s study of “The GoodReads ‘Classics’” have shown that the perception of what is “good” literature in these resources might also converge: the “classics” category of GoodReads overlaps with the classics in college syllabi. Similarly, a book’s sales-figures can correlate with newspapers’ review scores, canonical works tend to have a high number of library holdings on WorldCat, and so forth. While they offer us a glimpse into the complexity of the question, online resources can also be tools for exploring intriguing overlaps and divergences in the complex landscape of literary appreciation.
Sites like Goodreads can look like a window to reading culture “in the wild”, especially considering the large diversity and geographical spread of its nearly 90 million users. However, its democratic appearance may also obscure inherent biases, for example that most GoodReads users came from the U.S., so that the platform clearly shows a preference for anglophone literature. Biases in literary estimation may be resource or platform-specific, but may also have a more systematic nature. One difference or bias in literary appreciation is the one between reader-genders: Studies have shown that evaluation of literary quality between men and women reviewers clearly differs, for example between the more literary and the romantic genre – but also with regard to author-gender, where female authors are often graded lower by female reviewers, and male authors graded higher by male reviewers. In many ways, a sociological approach to the study of quality is relatively straightforward, and often it may be very helpful to a larger study to present the impact of certain works and authors.
A more difficult question to tackle, also without computers, is whether literary quality relates to intrinsic qualities or features of the texts. This is no trivial task, as many works that are considered masterpieces are difficult, if not impossible, to describe with a specific set of criteria. Moreover, one may ask how dependent any evaluation of literary quality is on the texts themselves: is it the features of a text are evaluated, or is it the context, the author, or any extra-textual information weighing in on our experience, including gender, race, sexuality, or nationality?
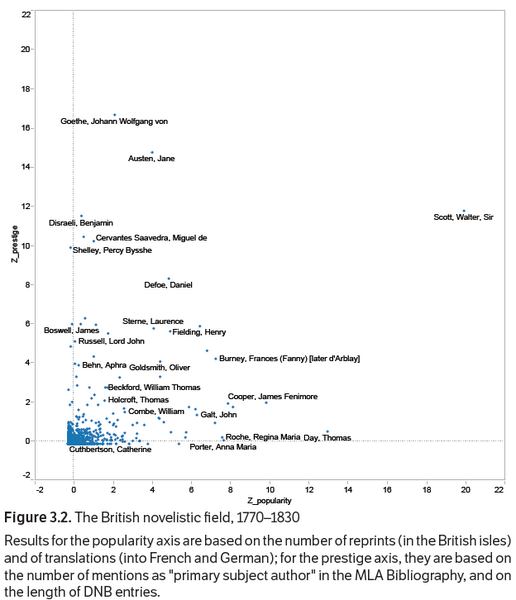
Among other institutions, Stanford Literary Lab has done interesting work on understanding canonical and noncanonical works, and has, for example, found significant differences in the predictability of word usage and other features weighing in on the longevity of a work. Overall, recent computational studies that link literary quality to features of the texts often look at global stylometric features, such as average sentence length, lexical richness, frequencies of certain parts of speech such as adverbs, or of syntactic sequences, or even measures like compressibility that estimates how “formulaic” a text is. Such studies often rely on one standard of literary appreciation to evaluate the weight of features for perceived quality or success, be it book sales, ratings on large user-platforms, literary prizes, canon-lists or appearances in canon-lists or syllabi, or a combination of them. In Jodie Archer and Matthew Jockers' The Bestseller Code, for example, the authors use thousands of parameters in a model that was able to predict whether a book was a bestseller or not. In the Netherlands-based project The Riddle of Literary Quality, Koolen et al. conducted an extensive study of what people mean when they talk of quality, asking readers to distinguish between “overall quality” and “literary quality”, and found that a combination of stylistic features and metadata features (such as genre) were very effective in predicting what readers thought of a work.
Beyond stylistic features, more complex features of narrative also have an impact on reading experience and that are more tightly bound to content, plot or progression. Recent studies, such as by Bizzoni et al., have applied sentiment analysis to narratives and found a correlation between the general valuation of works and the predictability of the narrative, with indications that there is a “Goldilocks zone,” where the narrative is neither too chaotic nor too predictable. Estimating more complex characteristics of narrative, content, tone, and style are exciting areas of computational literary studies that are rapidly developing.
So, although modeling literary quality is complex, there are certainly things that may be accomplished, particularly to understand larger corpora of texts, but also when trying to build such models, to better understand the attraction of literature and of certain authors or texts.
Applications
Elementary
Compare how different websites rank literature – both in terms of ratings and sales. Amazon, for example, has an accessible and constantly updating list that ranks how well books sell. While book sales can hardly be said to be the be-all and end-all measure of literary quality, it is certainly telling of a book’s general popularity and a reminder that literature, amongst other things, is also a marketable product. Which qualities does George Orwell’s Nineteen Eighty-Four for example possess that led it to be catapulted to the top of Amazon’s book sales in 2017, and what does it say about the preferences of Amazon’s book buying customers?

Open Syllabus is also an accessible site for comparing the popularity of authors or titles in a more institutional context, namely college syllabi. The Open Syllabus Galaxy is an interactive infographic of titles assigned in syllabi and interconnections between fields. Try to inspect their “map” of syllabi-titles, seeing which books are often co-assigned in, for example, film and literature syllabi, click on titles to see how often a title is assigned in which different fields (literature, history, philosophy, etc.), or explore titles in different topics, such as “science fiction”.
Another source is Goodreads, a social network site dedicated to reading, reviewing, and discussing books, meaning that user reviews are available for a vast selection of literature, especially for titles available in English. Information from Goodreads reviews can be derived in an automated way by scraping with the Goodreads API and afterwards analysed using computational approaches. However, scraping web data is not easy and quickly becomes a rather complicated task. You can, however, approach Goodreads reviews in a similar yet more simple way by creating your own database by manually compiling data from different sources into a spreadsheet using e.g., Microsoft Excel or Google Sheets. The data in your spreadsheet can be visualized afterwards using some of the freely available web applications allowing for all kinds of visualizations of spreadsheet data such as RawGraphs by Density Design.
Although user reviews from Goodreads are also not to be simply equated with literary quality, they can be seen as one of many ways to measure and discuss literary quality. Which qualities, for example, have led 6.6 million users to give Harry Potter and the Sorcerer's Stone an average rating of 4.47/5.00, and what does it say about the renowned scholar and critic Harold Bloom’s understanding of literary quality that he famously wrote a strongly negative review of precisely that book in the Wall Street Journal?
See Mads Rosendahl Thomsen’s “From Data to Actual Context” for an elaborated discussion of the relationship between circulation and quality and what role websites like Goodreads and Amazon might play in such debates.
One way to dive into the complexity of literary qualities is to look at differences in institutional or user-defined resources. Compare, for example, the scores of sites such as Open Syllabus, Amazon, and Goodreads. What are the Open Syllabus number of appearances, their library holdings on WorldCat, as well as GoodReads and Amazon ratings of some works of fiction? The Odyssey, for example, is very often listed in syllabi, has a high number of holdings on WorldCat, but has a relatively low rating on GoodReads. In comparison, Harry Potter and the Sorcerer’s Stone, which has a high rating on Goodreads and a lower number of appearances in Open Syllabus. For a study of a certain authorship, it may be interesting to see how the author’s books rank in these resources respectively: are some of the author’s books highlighted in education and others more popular among laymen readers?
Advanced
The computational study of literary quality is relatively new, and research in it is very exploratory. As algorithms do not have any prior knowledge or assumptions about literature and what “good” literature should be like, they have the potential to teach us humans something new about the characteristics of literary quality.
Pioneering work in the field has discovered some interesting implications of literary quality. Comparing prominent and obscure works (see Underwood, 2016, and Algee-Hewitt et al., 2016) implies that algorithms can successfully classify canonical works. The notion of quality is therefore not fully arbitrary, and literary language seems to have some intrinsic features that can be approximated through e.g., sentence length, vocabulary richness, and compressibility.
Explore ‘literariness’ as a textual feature from a data-driven approach by replicating an analysis done by van Cranenburgh and Bod (2017). Run an example with a toy dataset from Project Gutenberg using Cranenburgh's original code from their GitHub repository. The model predicts the number of downloads based on extracted text features. Collect your own corpus of texts and combine it with a quality score, for instance the GoodReads ratings of the texts, to see how the model performs on a new dataset.
For a more simple approach, use the functions “oppose” and “classify” of the Stylo package in R on a corpus of texts classified as “high-literary” and “low-literary” documents. Does the report reveal any notable insights into the syntactic or lexical features of your corpus? Maharjan et al. have made a corpus available that spans various genres and is divided into successful and unsuccessful books (with ratings above or below 3.5 on GoodReads), which might be easily explored in this way.
For diving deeper into GoodReads reviews, a big dataset is freely available. Using, for example, Python and matplotlib, titles with the most popular books, both with regard to average rating, rating count, or number of text-reviews may be explored, or correlations can be done between the rating and year of publication or text-length.
Resources
Scripts and sites
- The Riddle of Literary Quality, a Dutch research project on literary quality.
- Van Cranenburgh’s GitHub repository for evaluating literariness.
- Open Syllabus, a non-profit collection of college curriculum across 7,292,573 syllabi.
- WorldCat, a search-tool for titles and information about them supported by the OCLC, a nonprofit global library organization.
- Stylometry in R with the "Stylo" package in a nutshell.
- Dataset of titles and GoodReads data.
- Maharjan et al.’s dataset of sucessfull and unsucessfull books.
Sources
- Archer, J., & Jockers, M. L. (2017). The bestseller code. Penguin books.
- Ashok, V. G., Feng, S., & Choi, Y. (2013, October). Success with style: Using writing style to predict the success of novels. In Proceedings of the 2013 conference on empirical methods in natural language processing (pp. 1753-1764). https://www.aclweb.org/anthology/D13-1181.pdf
- Bizzoni, Y., Lassen, I. M., Peura, T., Thomsen, M. R., & Nielbo, K. (2022). Predicting Literary Quality How Perspectivist Should We Be? Proceedings of the 1st Workshop on Perspectivist Approaches to NLP @LREC2022, 20–25. https://aclanthology.org/2022.nlperspectives-1.3
- Bizzoni, Y., Nielbo, K. L., Peura, T., & Thomsen, M. R. (2021). Sentiment Dynamics of Success: Fractal Scaling of Story Arcs Predicts Reader Preferences. Proceedings of the Workshop on Natural Language Processing for Digital Humanities, 1–6.
- Fischer Wiki, Algee-Hewitt, Marc, et al. (2016). Canon/Archive. Large-scale Dynamics in the Literary Field" Stanford Literary Lab Pamphlet 11.https://litlab.stanford.edu/LiteraryLabPamphlet11.pdf
- Koolen, C., van Dalen-Oskam, K., Cranenburgh, A. van, & Nagelhout, E. (2020). Literary quality in the eye of the Dutch reader - The National Reader Survey. Poetics, 79. doi.org/10.1016/j.poetic.2020.101439
- Lassen, I. M. S., Bizzoni, Y., Peura, T., Thomsen, M. R., & Nielbo, K. L. (2022). Reviewer Preferences and Gender Disparities in Aesthetic Judgments (arXiv:2206.08697). arXiv. http://arxiv.org/abs/2206.08697
- Maharjan, S., Kar, S., Montes-y-Gomez, M., Gonzalez, F. A., & Solorio, T. (2018). Letting Emotions Flow: Success Prediction by Modeling the Flow of Emotions in Books. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol. 2). Association for Computational Linguistics. aclanthology.org/N18-2042
- Thomsen, M., R. (2019). From Data to Actual Context. In J. Ladegaard and J. G. Nielsen (Eds.) Context in Literary and Cultural Studies. (pp. 190-209). UCL Press. https://doi.org/10.14324/111.9781787356245
- Touileb, S., Øvrelid, L., & Velldal, E. (2020). Gender and sentiment, critics and authors: A dataset of Norwegian book reviews. Proceedings of the Second Workshop on Gender Bias in Natural Language Processing, 125–138. aclanthology.org/2020.gebnlp-1.11Underwood, T., & Sellers, J. (2016). The Longue Durée of literary prestige. Modern Language Quarterly, 77(3), 321-344. https://doi.org/10.1215/00267929-3570634
- van Cranenburgh, A., & Bod, R. (2017). A Data-Oriented Model of Literary Language. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, 1228–1238. aclanthology.org/E17-1115
- Walsh, M., & Antoniak, M. (2021). The GoodReads ‘Classics’: A Computational Study of Readers, Amazon, and Crowdsourced Amateur Criticism. Post45. https://post45.org/2021/04/the-goodreads-classics-a-computational-study-of-readers-amazon-and-crowdsourced-amateur-criticism/